Data Structures | |
| class | Flags |
| class | NestedDict |
| class | Output |
| class | TOMLDecodeError |
Functions | |
| dict[str, Any] | load (BinaryIO __fp, *ParseFloat parse_float=float) |
| dict[str, Any] | loads (str __s, *ParseFloat parse_float=float) |
| Pos | skip_chars (str src, Pos pos, Iterable[str] chars) |
| Pos | skip_until (str src, Pos pos, str expect, *frozenset[str] error_on, bool error_on_eof) |
| Pos | skip_comment (str src, Pos pos) |
| Pos | skip_comments_and_array_ws (str src, Pos pos) |
| tuple[Pos, Key] | create_dict_rule (str src, Pos pos, Output out) |
| tuple[Pos, Key] | create_list_rule (str src, Pos pos, Output out) |
| Pos | key_value_rule (str src, Pos pos, Output out, Key header, ParseFloat parse_float) |
| tuple[Pos, Key, Any] | parse_key_value_pair (str src, Pos pos, ParseFloat parse_float) |
| tuple[Pos, Key] | parse_key (str src, Pos pos) |
| tuple[Pos, str] | parse_key_part (str src, Pos pos) |
| tuple[Pos, str] | parse_one_line_basic_str (str src, Pos pos) |
| tuple[Pos, list] | parse_array (str src, Pos pos, ParseFloat parse_float) |
| tuple[Pos, dict] | parse_inline_table (str src, Pos pos, ParseFloat parse_float) |
| tuple[Pos, str] | parse_basic_str_escape (str src, Pos pos, *bool multiline=False) |
| tuple[Pos, str] | parse_basic_str_escape_multiline (str src, Pos pos) |
| tuple[Pos, str] | parse_hex_char (str src, Pos pos, int hex_len) |
| tuple[Pos, str] | parse_literal_str (str src, Pos pos) |
| tuple[Pos, str] | parse_multiline_str (str src, Pos pos, *bool literal) |
| tuple[Pos, str] | parse_basic_str (str src, Pos pos, *bool multiline) |
| tuple[Pos, Any] | parse_value (str src, Pos pos, ParseFloat parse_float) |
| TOMLDecodeError | suffixed_err (str src, Pos pos, str msg) |
| bool | is_unicode_scalar_value (int codepoint) |
| ParseFloat | make_safe_parse_float (ParseFloat parse_float) |
Variables | |
| ASCII_CTRL = frozenset(chr(i) for i in range(32)) | frozenset(chr(127)) | |
| ILLEGAL_BASIC_STR_CHARS = ASCII_CTRL - frozenset("\t") | |
| ILLEGAL_MULTILINE_BASIC_STR_CHARS = ASCII_CTRL - frozenset("\t\n") | |
| ILLEGAL_LITERAL_STR_CHARS = ILLEGAL_BASIC_STR_CHARS | |
| ILLEGAL_MULTILINE_LITERAL_STR_CHARS = ILLEGAL_MULTILINE_BASIC_STR_CHARS | |
| ILLEGAL_COMMENT_CHARS = ILLEGAL_BASIC_STR_CHARS | |
| TOML_WS = frozenset(" \t") | |
| TOML_WS_AND_NEWLINE = TOML_WS | frozenset("\n") | |
| BARE_KEY_CHARS = frozenset(string.ascii_letters + string.digits + "-_") | |
| KEY_INITIAL_CHARS = BARE_KEY_CHARS | frozenset("\"'") | |
| HEXDIGIT_CHARS = frozenset(string.hexdigits) | |
| BASIC_STR_ESCAPE_REPLACEMENTS | |
Function Documentation
◆ create_dict_rule()
| tuple[Pos, Key] create_dict_rule | ( | str | src, |
| Pos | pos, | ||
| Output | out | ||
| ) |
Definition at line 284 of file _parser.py.
References i, pip._vendor.tomli._parser.parse_key(), pip._vendor.tomli._parser.skip_chars(), and pip._vendor.tomli._parser.suffixed_err().
Referenced by pip._vendor.tomli._parser.loads().

◆ create_list_rule()
| tuple[Pos, Key] create_list_rule | ( | str | src, |
| Pos | pos, | ||
| Output | out | ||
| ) |
Definition at line 302 of file _parser.py.
References i, pip._vendor.tomli._parser.parse_key(), pip._vendor.tomli._parser.skip_chars(), and pip._vendor.tomli._parser.suffixed_err().
Referenced by pip._vendor.tomli._parser.loads().

◆ is_unicode_scalar_value()
| bool is_unicode_scalar_value | ( | int | codepoint | ) |
Definition at line 669 of file _parser.py.
Referenced by pip._vendor.tomli._parser.parse_hex_char().

◆ key_value_rule()
| Pos key_value_rule | ( | str | src, |
| Pos | pos, | ||
| Output | out, | ||
| Key | header, | ||
| ParseFloat | parse_float | ||
| ) |
Definition at line 323 of file _parser.py.
References i, pip._vendor.tomli._parser.parse_key_value_pair(), and pip._vendor.tomli._parser.suffixed_err().
Referenced by pip._vendor.tomli._parser.loads().

◆ load()
| dict[str, Any] load | ( | BinaryIO | __fp, |
| *ParseFloat | parse_float = float |
||
| ) |
Parse TOML from a binary file object.
Definition at line 57 of file _parser.py.
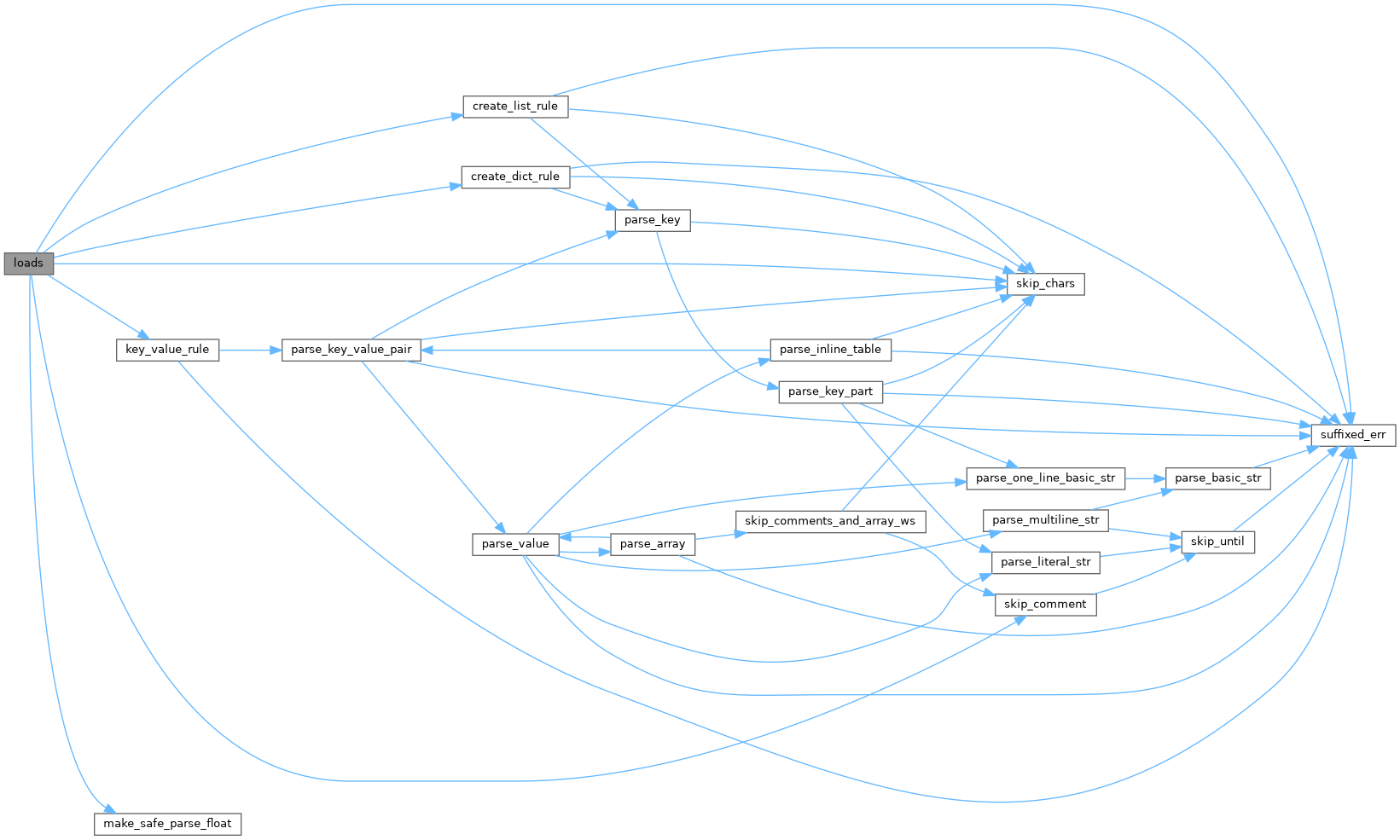
◆ loads()
| dict[str, Any] loads | ( | str | __s, |
| *ParseFloat | parse_float = float |
||
| ) |
Parse TOML from a string.
Definition at line 69 of file _parser.py.
References pip._vendor.tomli._parser.create_dict_rule(), pip._vendor.tomli._parser.create_list_rule(), i, pip._vendor.tomli._parser.key_value_rule(), pip._vendor.tomli._parser.make_safe_parse_float(), pip._vendor.tomli._parser.skip_chars(), pip._vendor.tomli._parser.skip_comment(), and pip._vendor.tomli._parser.suffixed_err().
◆ make_safe_parse_float()
| ParseFloat make_safe_parse_float | ( | ParseFloat | parse_float | ) |
A decorator to make `parse_float` safe. `parse_float` must not return dicts or lists, because these types would be mixed with parsed TOML tables and arrays, thus confusing the parser. The returned decorated callable raises `ValueError` instead of returning illegal types.
Definition at line 673 of file _parser.py.
References i.
Referenced by pip._vendor.tomli._parser.loads().

◆ parse_array()
| tuple[Pos, list] parse_array | ( | str | src, |
| Pos | pos, | ||
| ParseFloat | parse_float | ||
| ) |
Definition at line 412 of file _parser.py.
References i, pip._vendor.tomli._parser.parse_value(), pip._vendor.tomli._parser.skip_comments_and_array_ws(), and pip._vendor.tomli._parser.suffixed_err().
Referenced by pip._vendor.tomli._parser.parse_value().

◆ parse_basic_str()
| tuple[Pos, str] parse_basic_str | ( | str | src, |
| Pos | pos, | ||
| *bool | multiline | ||
| ) |
Definition at line 552 of file _parser.py.
References i, and pip._vendor.tomli._parser.suffixed_err().
Referenced by pip._vendor.tomli._parser.parse_multiline_str(), and pip._vendor.tomli._parser.parse_one_line_basic_str().


◆ parse_basic_str_escape()
| tuple[Pos, str] parse_basic_str_escape | ( | str | src, |
| Pos | pos, | ||
| *bool | multiline = False |
||
| ) |
Definition at line 468 of file _parser.py.
References pip._vendor.tomli._parser.parse_hex_char(), pip._vendor.tomli._parser.skip_chars(), and pip._vendor.tomli._parser.suffixed_err().
Referenced by pip._vendor.tomli._parser.parse_basic_str_escape_multiline().

◆ parse_basic_str_escape_multiline()
| tuple[Pos, str] parse_basic_str_escape_multiline | ( | str | src, |
| Pos | pos | ||
| ) |
Definition at line 497 of file _parser.py.
References pip._vendor.tomli._parser.parse_basic_str_escape().

◆ parse_hex_char()
| tuple[Pos, str] parse_hex_char | ( | str | src, |
| Pos | pos, | ||
| int | hex_len | ||
| ) |
Definition at line 501 of file _parser.py.
References i, pip._vendor.tomli._parser.is_unicode_scalar_value(), and pip._vendor.tomli._parser.suffixed_err().
Referenced by pip._vendor.tomli._parser.parse_basic_str_escape().

◆ parse_inline_table()
| tuple[Pos, dict] parse_inline_table | ( | str | src, |
| Pos | pos, | ||
| ParseFloat | parse_float | ||
| ) |
Definition at line 436 of file _parser.py.
References i, pip._vendor.tomli._parser.parse_key_value_pair(), pip._vendor.tomli._parser.skip_chars(), and pip._vendor.tomli._parser.suffixed_err().
Referenced by pip._vendor.tomli._parser.parse_value().

◆ parse_key()
| tuple[Pos, Key] parse_key | ( | str | src, |
| Pos | pos | ||
| ) |
Definition at line 373 of file _parser.py.
References pip._vendor.tomli._parser.parse_key_part(), and pip._vendor.tomli._parser.skip_chars().
Referenced by pip._vendor.tomli._parser.create_dict_rule(), pip._vendor.tomli._parser.create_list_rule(), and pip._vendor.tomli._parser.parse_key_value_pair().
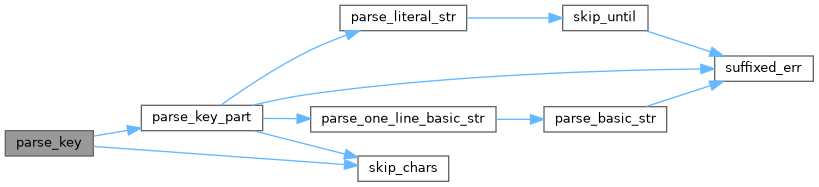
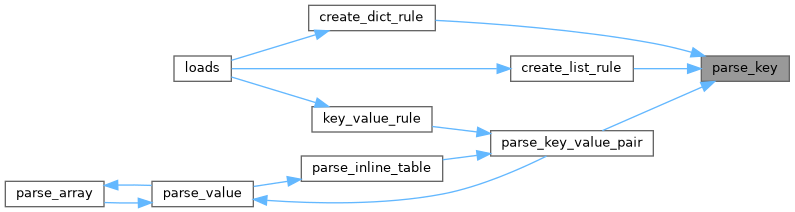
◆ parse_key_part()
| tuple[Pos, str] parse_key_part | ( | str | src, |
| Pos | pos | ||
| ) |
Definition at line 391 of file _parser.py.
References pip._vendor.tomli._parser.parse_literal_str(), pip._vendor.tomli._parser.parse_one_line_basic_str(), pip._vendor.tomli._parser.skip_chars(), and pip._vendor.tomli._parser.suffixed_err().
Referenced by pip._vendor.tomli._parser.parse_key().
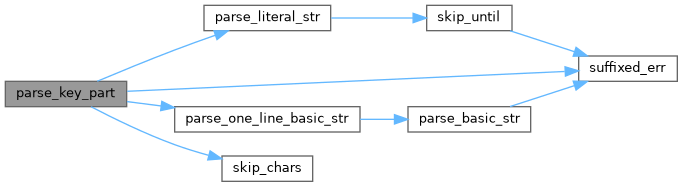
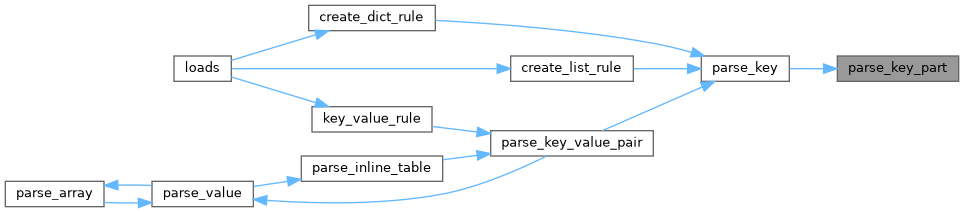
◆ parse_key_value_pair()
| tuple[Pos, Key, Any] parse_key_value_pair | ( | str | src, |
| Pos | pos, | ||
| ParseFloat | parse_float | ||
| ) |
Definition at line 357 of file _parser.py.
References pip._vendor.tomli._parser.parse_key(), pip._vendor.tomli._parser.parse_value(), pip._vendor.tomli._parser.skip_chars(), and pip._vendor.tomli._parser.suffixed_err().
Referenced by pip._vendor.tomli._parser.key_value_rule(), and pip._vendor.tomli._parser.parse_inline_table().

◆ parse_literal_str()
| tuple[Pos, str] parse_literal_str | ( | str | src, |
| Pos | pos | ||
| ) |
Definition at line 512 of file _parser.py.
References pip._vendor.tomli._parser.skip_until().
Referenced by pip._vendor.tomli._parser.parse_key_part(), and pip._vendor.tomli._parser.parse_value().

◆ parse_multiline_str()
| tuple[Pos, str] parse_multiline_str | ( | str | src, |
| Pos | pos, | ||
| *bool | literal | ||
| ) |
Definition at line 521 of file _parser.py.
References i, pip._vendor.tomli._parser.parse_basic_str(), and pip._vendor.tomli._parser.skip_until().
Referenced by pip._vendor.tomli._parser.parse_value().


◆ parse_one_line_basic_str()
| tuple[Pos, str] parse_one_line_basic_str | ( | str | src, |
| Pos | pos | ||
| ) |
Definition at line 407 of file _parser.py.
References pip._vendor.tomli._parser.parse_basic_str().
Referenced by pip._vendor.tomli._parser.parse_key_part(), and pip._vendor.tomli._parser.parse_value().

◆ parse_value()
| tuple[Pos, Any] parse_value | ( | str | src, |
| Pos | pos, | ||
| ParseFloat | parse_float | ||
| ) |
Definition at line 584 of file _parser.py.
References i, pip._vendor.tomli._parser.parse_array(), pip._vendor.tomli._parser.parse_inline_table(), pip._vendor.tomli._parser.parse_literal_str(), pip._vendor.tomli._parser.parse_multiline_str(), pip._vendor.tomli._parser.parse_one_line_basic_str(), and pip._vendor.tomli._parser.suffixed_err().
Referenced by pip._vendor.tomli._parser.parse_array(), and pip._vendor.tomli._parser.parse_key_value_pair().
◆ skip_chars()
| Pos skip_chars | ( | str | src, |
| Pos | pos, | ||
| Iterable[str] | chars | ||
| ) |
Definition at line 232 of file _parser.py.
Referenced by pip._vendor.tomli._parser.create_dict_rule(), pip._vendor.tomli._parser.create_list_rule(), pip._vendor.tomli._parser.loads(), pip._vendor.tomli._parser.parse_basic_str_escape(), pip._vendor.tomli._parser.parse_inline_table(), pip._vendor.tomli._parser.parse_key(), pip._vendor.tomli._parser.parse_key_part(), pip._vendor.tomli._parser.parse_key_value_pair(), and pip._vendor.tomli._parser.skip_comments_and_array_ws().
◆ skip_comment()
| Pos skip_comment | ( | str | src, |
| Pos | pos | ||
| ) |
Definition at line 263 of file _parser.py.
References pip._vendor.tomli._parser.skip_until().
Referenced by pip._vendor.tomli._parser.loads(), and pip._vendor.tomli._parser.skip_comments_and_array_ws().


◆ skip_comments_and_array_ws()
| Pos skip_comments_and_array_ws | ( | str | src, |
| Pos | pos | ||
| ) |
Definition at line 275 of file _parser.py.
References pip._vendor.tomli._parser.skip_chars(), and pip._vendor.tomli._parser.skip_comment().
Referenced by pip._vendor.tomli._parser.parse_array().


◆ skip_until()
| Pos skip_until | ( | str | src, |
| Pos | pos, | ||
| str | expect, | ||
| *frozenset[str] | error_on, | ||
| bool | error_on_eof | ||
| ) |
Definition at line 241 of file _parser.py.
References i, and pip._vendor.tomli._parser.suffixed_err().
Referenced by pip._vendor.tomli._parser.parse_literal_str(), pip._vendor.tomli._parser.parse_multiline_str(), and pip._vendor.tomli._parser.skip_comment().

◆ suffixed_err()
| TOMLDecodeError suffixed_err | ( | str | src, |
| Pos | pos, | ||
| str | msg | ||
| ) |
Return a `TOMLDecodeError` where error message is suffixed with coordinates in source.
Definition at line 652 of file _parser.py.
References i.
Referenced by pip._vendor.tomli._parser.create_dict_rule(), pip._vendor.tomli._parser.create_list_rule(), pip._vendor.tomli._parser.key_value_rule(), pip._vendor.tomli._parser.loads(), pip._vendor.tomli._parser.parse_array(), pip._vendor.tomli._parser.parse_basic_str(), pip._vendor.tomli._parser.parse_basic_str_escape(), pip._vendor.tomli._parser.parse_hex_char(), pip._vendor.tomli._parser.parse_inline_table(), pip._vendor.tomli._parser.parse_key_part(), pip._vendor.tomli._parser.parse_key_value_pair(), pip._vendor.tomli._parser.parse_value(), and pip._vendor.tomli._parser.skip_until().
Variable Documentation
◆ ASCII_CTRL
Definition at line 22 of file _parser.py.
◆ BARE_KEY_CHARS
| BARE_KEY_CHARS = frozenset(string.ascii_letters + string.digits + "-_") |
Definition at line 36 of file _parser.py.
◆ BASIC_STR_ESCAPE_REPLACEMENTS
| BASIC_STR_ESCAPE_REPLACEMENTS |
Definition at line 40 of file _parser.py.
◆ HEXDIGIT_CHARS
| HEXDIGIT_CHARS = frozenset(string.hexdigits) |
Definition at line 38 of file _parser.py.
◆ ILLEGAL_BASIC_STR_CHARS
| ILLEGAL_BASIC_STR_CHARS = ASCII_CTRL - frozenset("\t") |
Definition at line 26 of file _parser.py.
◆ ILLEGAL_COMMENT_CHARS
| ILLEGAL_COMMENT_CHARS = ILLEGAL_BASIC_STR_CHARS |
Definition at line 32 of file _parser.py.
◆ ILLEGAL_LITERAL_STR_CHARS
| ILLEGAL_LITERAL_STR_CHARS = ILLEGAL_BASIC_STR_CHARS |
Definition at line 29 of file _parser.py.
◆ ILLEGAL_MULTILINE_BASIC_STR_CHARS
| ILLEGAL_MULTILINE_BASIC_STR_CHARS = ASCII_CTRL - frozenset("\t\n") |
Definition at line 27 of file _parser.py.
◆ ILLEGAL_MULTILINE_LITERAL_STR_CHARS
| ILLEGAL_MULTILINE_LITERAL_STR_CHARS = ILLEGAL_MULTILINE_BASIC_STR_CHARS |
Definition at line 30 of file _parser.py.
◆ KEY_INITIAL_CHARS
| KEY_INITIAL_CHARS = BARE_KEY_CHARS | frozenset("\"'") |
Definition at line 37 of file _parser.py.
◆ TOML_WS
| TOML_WS = frozenset(" \t") |
Definition at line 34 of file _parser.py.
◆ TOML_WS_AND_NEWLINE
Definition at line 35 of file _parser.py.