Public Member Functions | |
| None | __init__ (self, str url, Optional[Union[str, "IndexContent"]] comes_from=None, Optional[str] requires_python=None, Optional[str] yanked_reason=None, Optional[MetadataFile] metadata_file_data=None, bool cache_link_parsing=True, Optional[Mapping[str, str]] hashes=None) |
| Optional["Link"] | from_json (cls, Dict[str, Any] file_data, str page_url) |
| Optional["Link"] | from_element (cls, Dict[str, Optional[str]] anchor_attribs, str page_url, str base_url) |
| str | __str__ (self) |
| str | __repr__ (self) |
| str | url (self) |
| str | filename (self) |
| str | file_path (self) |
| str | scheme (self) |
| str | netloc (self) |
| str | path (self) |
| Tuple[str, str] | splitext (self) |
| str | ext (self) |
| str | url_without_fragment (self) |
| Optional[str] | subdirectory_fragment (self) |
| Optional["Link"] | metadata_link (self) |
| Hashes | as_hashes (self) |
| Optional[str] | hash (self) |
| Optional[str] | hash_name (self) |
| str | show_url (self) |
| bool | is_file (self) |
| bool | is_existing_dir (self) |
| bool | is_wheel (self) |
| bool | is_vcs (self) |
| bool | is_yanked (self) |
| bool | has_hash (self) |
| bool | is_hash_allowed (self, Optional[Hashes] hashes) |
 Public Member Functions inherited from KeyBasedCompareMixin Public Member Functions inherited from KeyBasedCompareMixin | |
| int | __hash__ (self) |
| bool | __lt__ (self, Any other) |
| bool | __le__ (self, Any other) |
| bool | __gt__ (self, Any other) |
| bool | __ge__ (self, Any other) |
| bool | __eq__ (self, Any other) |
Data Fields | |
| comes_from | |
| requires_python | |
| yanked_reason | |
| metadata_file_data | |
| cache_link_parsing | |
| egg_fragment | |
| url | |
| scheme | |
| file_path | |
| ext | |
Protected Member Functions | |
| Optional[str] | _egg_fragment (self) |
| Protected Member Functions inherited from KeyBasedCompareMixin | |
| bool | _compare (self, Any other, Callable[[Any, Any], bool] method) |
Protected Attributes | |
| _parsed_url | |
| _url | |
| _hashes | |
| Protected Attributes inherited from KeyBasedCompareMixin | |
| _compare_key | |
| _defining_class | |
Static Protected Attributes | |
| _egg_fragment_re = re.compile(r"[#&]egg=([^&]*)") | |
| _project_name_re | |
| _subdirectory_fragment_re = re.compile(r"[#&]subdirectory=([^&]*)") | |
Detailed Description
Constructor & Destructor Documentation
◆ __init__()
| None __init__ | ( | self, | |
| str | url, | ||
| Optional[Union[str, "IndexContent"]] | comes_from = None, |
||
| Optional[str] | requires_python = None, |
||
| Optional[str] | yanked_reason = None, |
||
| Optional[MetadataFile] | metadata_file_data = None, |
||
| bool | cache_link_parsing = True, |
||
| Optional[Mapping[str, str]] | hashes = None |
||
| ) |
:param url: url of the resource pointed to (href of the link)
:param comes_from: instance of IndexContent where the link was found,
or string.
:param requires_python: String containing the `Requires-Python`
metadata field, specified in PEP 345. This may be specified by
a data-requires-python attribute in the HTML link tag, as
described in PEP 503.
:param yanked_reason: the reason the file has been yanked, if the
file has been yanked, or None if the file hasn't been yanked.
This is the value of the "data-yanked" attribute, if present, in
a simple repository HTML link. If the file has been yanked but
no reason was provided, this should be the empty string. See
PEP 592 for more information and the specification.
:param metadata_file_data: the metadata attached to the file, or None if
no such metadata is provided. This argument, if not None, indicates
that a separate metadata file exists, and also optionally supplies
hashes for that file.
:param cache_link_parsing: A flag that is used elsewhere to determine
whether resources retrieved from this link should be cached. PyPI
URLs should generally have this set to False, for example.
:param hashes: A mapping of hash names to digests to allow us to
determine the validity of a download.
Reimplemented from KeyBasedCompareMixin.
Definition at line 197 of file link.py.
References i.
Referenced by Protocol.__init_subclass__().

Member Function Documentation
◆ __repr__()
| str __repr__ | ( | self | ) |
◆ __str__()
| str __str__ | ( | self | ) |
Definition at line 365 of file link.py.
References Link._url, LazyZipOverHTTP._url, Link.comes_from, ParsedRequirement.comes_from, InstallRequirement.comes_from, BaseDistribution.requires_python(), and Link.requires_python.
◆ _egg_fragment()
|
protected |
Definition at line 436 of file link.py.
References Link._egg_fragment_re, Link._project_name_re, Link._url, LazyZipOverHTTP._url, and i.
◆ as_hashes()
| Hashes as_hashes | ( | self | ) |
Definition at line 472 of file link.py.
References CandidateEvaluator._hashes, and Link._hashes.
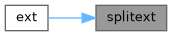
◆ ext()
| str ext | ( | self | ) |
Definition at line 421 of file link.py.
References Link.splitext().
◆ file_path()
| str file_path | ( | self | ) |
◆ filename()
| str filename | ( | self | ) |
Definition at line 385 of file link.py.
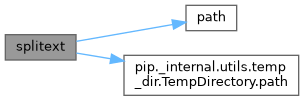
References i, PackageIndex.netloc, Link.netloc(), Url.netloc(), _Prefix.path, Link.path(), File.path, TempDirectory.path(), _Cache.path, DistributionPath.path, BaseInstalledDistribution.path, InstalledDistribution.path, EggInfoDistribution.path, and FileMetadata.path.
Referenced by Wheel._get_extensions(), HtmlFormatter._wrap_pre(), HtmlFormatter._wrap_tablelinenos(), Wheel.exists(), Wheel.info(), Wheel.install(), Wheel.metadata(), Wheel.mount(), PyPIRCFile.read(), Wheel.unmount(), Wheel.update(), PyPIRCFile.update(), and Wheel.verify().
◆ from_element()
| Optional["Link"] from_element | ( | cls, | |
| Dict[str, Optional[str]] | anchor_attribs, | ||
| str | page_url, | ||
| str | base_url | ||
| ) |
Convert an anchor element's attributes in a simple repository page to a Link.
Definition at line 314 of file link.py.
References pip._internal.models.link._ensure_quoted_url(), i, and pip._internal.models.link.supported_hashes().

◆ from_json()
| Optional["Link"] from_json | ( | cls, | |
| Dict[str, Any] | file_data, | ||
| str | page_url | ||
| ) |
Convert an pypi json document from a simple repository page into a Link.
Definition at line 263 of file link.py.
References pip._internal.models.link._ensure_quoted_url(), i, and pip._internal.models.link.supported_hashes().

◆ has_hash()
| bool has_hash | ( | self | ) |
Definition at line 509 of file link.py.
References CandidateEvaluator._hashes, and Link._hashes.
◆ hash()
| Optional[str] hash | ( | self | ) |
Definition at line 476 of file link.py.
References CandidateEvaluator._hashes, and Link._hashes.
Referenced by ArchiveInfo._to_dict().

◆ hash_name()
| Optional[str] hash_name | ( | self | ) |
Definition at line 480 of file link.py.
References CandidateEvaluator._hashes, and Link._hashes.
◆ is_existing_dir()
| bool is_existing_dir | ( | self | ) |
◆ is_file()
| bool is_file | ( | self | ) |
Definition at line 488 of file link.py.
Referenced by BaseDistribution.requested().

◆ is_hash_allowed()
| bool is_hash_allowed | ( | self, | |
| Optional[Hashes] | hashes | ||
| ) |
Return True if the link has a hash and it is allowed by `hashes`.
Definition at line 512 of file link.py.
References CandidateEvaluator._hashes, Link._hashes, and i.
Referenced by Hashes.has_one_of().

◆ is_vcs()
| bool is_vcs | ( | self | ) |
Definition at line 499 of file link.py.
References i, Link.scheme(), Link.scheme, Locator.scheme, AggregatingLocator.scheme, LegacyMetadata.scheme, Metadata.scheme, ConnectionPool.scheme, HTTPConnectionPool.scheme, HTTPSConnectionPool.scheme, NTLMConnectionPool.scheme, and URLSchemeUnknown.scheme.

◆ is_wheel()
| bool is_wheel | ( | self | ) |
Definition at line 495 of file link.py.
Referenced by InstallRequirement.get_dist(), and InstallRequirement.install().

◆ is_yanked()
| bool is_yanked | ( | self | ) |
Definition at line 505 of file link.py.
References Link.yanked_reason.
◆ metadata_link()
| Optional["Link"] metadata_link | ( | self | ) |
Return a link to the associated core metadata file (if any).
Definition at line 463 of file link.py.
References Link.metadata_file_data.
◆ netloc()
| str netloc | ( | self | ) |
This can contain auth information.
Definition at line 407 of file link.py.
References Link._parsed_url.
Referenced by Link.filename().
◆ path()
| str path | ( | self | ) |
Definition at line 414 of file link.py.
References Link._parsed_url, and i.
Referenced by InstalledDistribution.__eq__(), EggInfoDistribution.__eq__(), DistributionPath._yield_distributions(), _Cache.add(), InstalledDistribution.check_installed_files(), EggInfoDistribution.check_installed_files(), _Cache.clear(), Link.filename(), InstalledDistribution.get_distinfo_file(), InstalledDistribution.get_distinfo_resource(), InstalledDistribution.list_distinfo_files(), EggInfoDistribution.list_distinfo_files(), EggInfoDistribution.list_installed_files(), Url.request_uri(), InstalledDistribution.shared_locations(), Link.splitext(), InstalledDistribution.write_installed_files(), and InstalledDistribution.write_shared_locations().
◆ scheme()
| str scheme | ( | self | ) |
Definition at line 403 of file link.py.
References Link._parsed_url.
Referenced by HTTPConnectionPool._absolute_url(), PyPIRPCLocator._get_project(), PyPIJSONLocator._get_project(), JSONLocator._get_project(), Locator._update_version_data(), Metadata._validate_value(), LegacyMetadata.check(), AggregatingLocator.get_distribution_names(), HTTPConnectionPool.is_same_host(), Link.is_vcs(), Locator.locate(), LegacyMetadata.set(), and Metadata.validate().
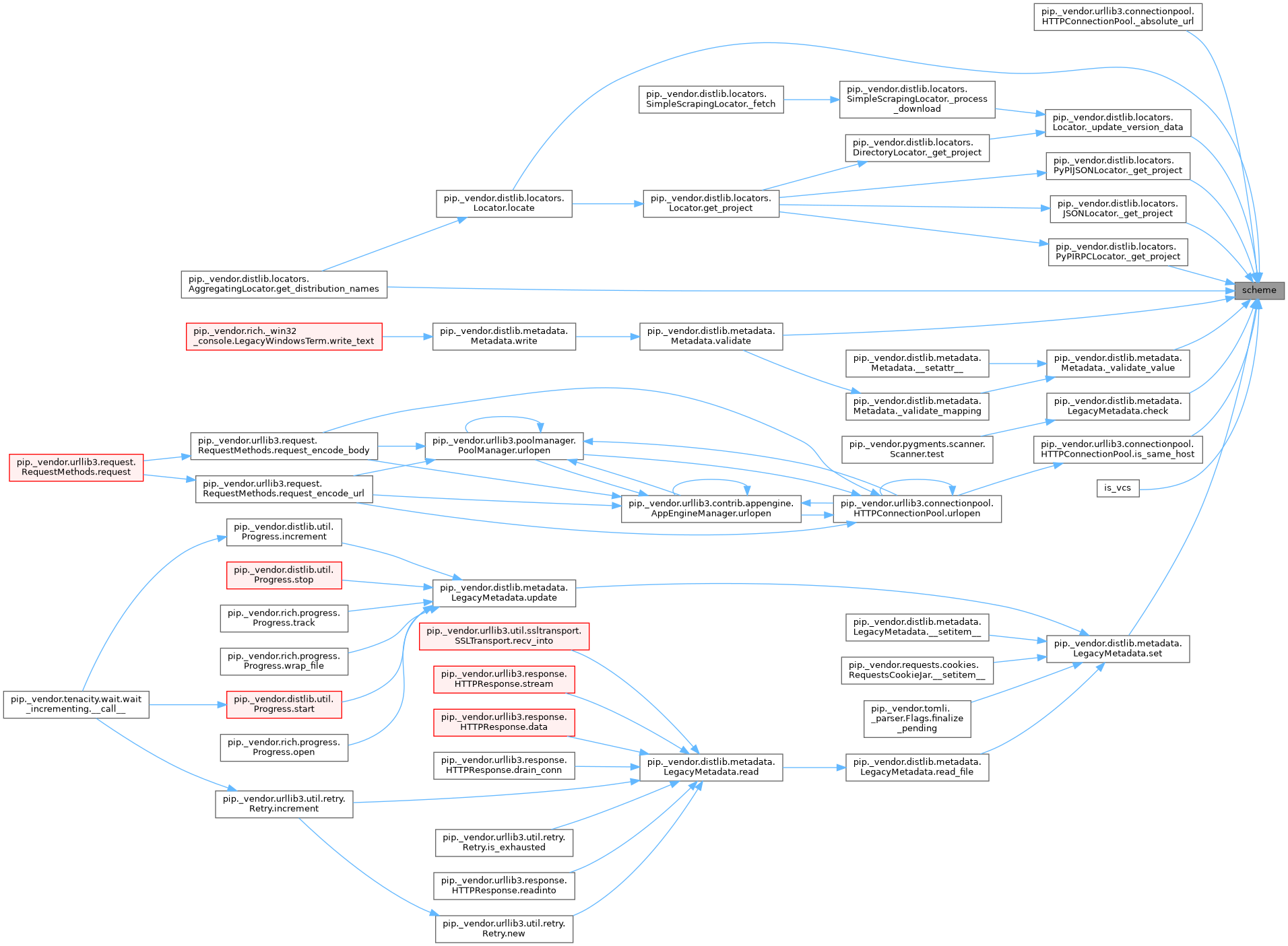
◆ show_url()
| str show_url | ( | self | ) |
Definition at line 484 of file link.py.
References Link._url, LazyZipOverHTTP._url, and i.
◆ splitext()
| Tuple[str, str] splitext | ( | self | ) |
Definition at line 417 of file link.py.
References i, _Prefix.path, Link.path(), File.path, TempDirectory.path(), _Cache.path, DistributionPath.path, BaseInstalledDistribution.path, InstalledDistribution.path, EggInfoDistribution.path, and FileMetadata.path.
Referenced by Link.ext().
◆ subdirectory_fragment()
| Optional[str] subdirectory_fragment | ( | self | ) |
Definition at line 457 of file link.py.
References Link._subdirectory_fragment_re, Link._url, LazyZipOverHTTP._url, and i.
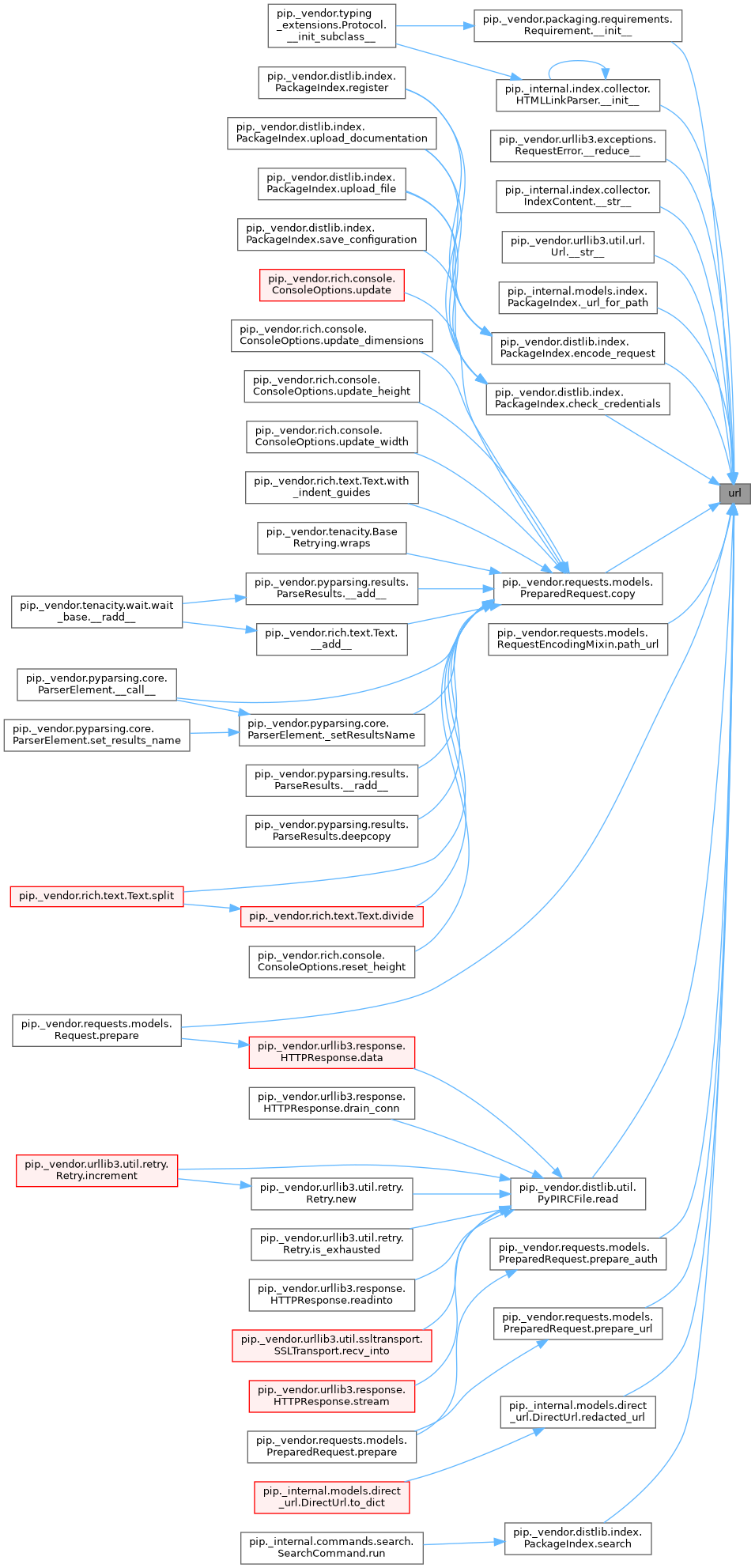
◆ url()
| str url | ( | self | ) |
Definition at line 381 of file link.py.
References Link._url, and LazyZipOverHTTP._url.
Referenced by Requirement.__init__(), HTMLLinkParser.__init__(), RequestError.__reduce__(), IndexContent.__str__(), Url.__str__(), PackageIndex._url_for_path(), PackageIndex.check_credentials(), PreparedRequest.copy(), PackageIndex.encode_request(), RequestEncodingMixin.path_url(), Request.prepare(), PreparedRequest.prepare_auth(), PreparedRequest.prepare_url(), PyPIRCFile.read(), DirectUrl.redacted_url(), and PackageIndex.search().
◆ url_without_fragment()
| str url_without_fragment | ( | self | ) |
Definition at line 425 of file link.py.
References Link._parsed_url, and i.
Field Documentation
◆ _egg_fragment_re
Definition at line 429 of file link.py.
Referenced by Link._egg_fragment().
◆ _hashes
|
protected |
Definition at line 248 of file link.py.
Referenced by CandidateEvaluator._sort_key(), Link.as_hashes(), CandidateEvaluator.get_applicable_candidates(), Link.has_hash(), Link.hash(), Link.hash_name(), and Link.is_hash_allowed().
◆ _parsed_url
|
protected |
Definition at line 240 of file link.py.
Referenced by Link.netloc(), Link.path(), Link.scheme(), and Link.url_without_fragment().
◆ _project_name_re
|
staticprotected |
Definition at line 432 of file link.py.
Referenced by Link._egg_fragment().
◆ _subdirectory_fragment_re
|
staticprotected |
Definition at line 454 of file link.py.
Referenced by Link.subdirectory_fragment().
◆ _url
|
protected |
Definition at line 243 of file link.py.
Referenced by Link.__str__(), Link._egg_fragment(), LazyZipOverHTTP._stream_response(), Link.show_url(), Link.subdirectory_fragment(), and Link.url().
◆ cache_link_parsing
◆ comes_from
| comes_from |
Definition at line 252 of file link.py.
Referenced by Link.__str__(), InstallRequirement.__str__(), and InstallRequirement.from_path().
◆ egg_fragment
◆ ext
◆ file_path
◆ metadata_file_data
| metadata_file_data |
Definition at line 255 of file link.py.
Referenced by Link.metadata_link().
◆ requires_python
| requires_python |
Definition at line 253 of file link.py.
Referenced by Link.__str__().
◆ scheme
| scheme |
Definition at line 489 of file link.py.
Referenced by HTTPConnectionPool._absolute_url(), PyPIRPCLocator._get_project(), PyPIJSONLocator._get_project(), JSONLocator._get_project(), Locator._update_version_data(), Metadata._validate_value(), LegacyMetadata.check(), AggregatingLocator.get_distribution_names(), HTTPConnectionPool.is_same_host(), Link.is_vcs(), Locator.locate(), LegacyMetadata.set(), and Metadata.validate().
◆ url
| url |
Definition at line 400 of file link.py.
Referenced by Requirement.__init__(), HTMLLinkParser.__init__(), RequestError.__reduce__(), IndexContent.__str__(), Url.__str__(), PackageIndex._url_for_path(), PackageIndex.check_credentials(), PreparedRequest.copy(), PackageIndex.encode_request(), RequestEncodingMixin.path_url(), Request.prepare(), PreparedRequest.prepare_auth(), PreparedRequest.prepare_url(), PyPIRCFile.read(), DirectUrl.redacted_url(), and PackageIndex.search().
◆ yanked_reason
| yanked_reason |
Definition at line 254 of file link.py.
Referenced by Link.is_yanked().
The documentation for this class was generated from the following file:
- /home/liwuen/projects_dev/pqc-engineering-ssec-23/venv/lib/python3.12/site-packages/pip/_internal/models/link.py